
이번에는 GROUP BY 절 과 ROLLUP, GROUPING SETS 등에 대해서 설명해보려고 한다. 밑의 employees 라는 테이블이 있다고
가정해보자.

이번에 GROUP BY 절을 통해서 DEPARTMENT_ID ( 부서번호) 부서별 SALARY 의 합을 구해주려고 한다.. 실행방법은 다음과 같고, 실행결과 또한 밑의 이미지와 같다.
SELECT department_id as 부서번호 , sum ( salary ) as 부서별월급합
FROM employees
GROUP BY department_id
ORDER BY 1 ; -- 좀더 편하게 보기위해서, 첫번째 컬럼인 department_id 로 오름차순 한 것이다.
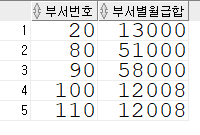
GROUP BY 절을 사용하여, 그룹함수의 값을 나타내었을 때는 그룹함수의 값이 특정 조건에 해당하는 것만 추출하고자 할 때 는 WHERE 절을 사용하는 것이 아니라 , HAVING 그룹함수 조건절을 사용해야 한다. 예를 들어서 , 부서별월급합이 20000 이상인 부서만 출력해보려고 한다.
SELECT department_id as 부서번호 , sum ( salary ) as 부서별월급합
FROM employees
GROUP BY department_id
HAVING sum(salary) > = 20000 -- 부서별월급합이 20000 이상인 부서만 출력하기 위한 것.
ORDER BY 1 ; -- 좀더 편하게 보기위해서, 첫번째 컬럼인 department_id 로 오름차순 한 것이다.

다음으로 , GROUPING SETS 를 이용해서 부서별 어떠한 인원들이 존재하는지 알아보려고 한다. 부서별 인원들의 성, 이름 , 사원번호를 출력하고자 한다. 이에 대한 실행방법과 실행결과는 다음과 같다.
SELECT department_id as 부서번호 , first_name as 성 , last_name as 이름, employee_id as 사원번호
FROM employees
GROUP BY department_id , grouping sets( first_name ) , grouping sets( last_name ) , grouping sets ( employee_id )

----- >>>>> 요약값(rollup, cube, grouping sets) <<<<< ------
/*
1. rollup(a,b,c) 은 grouping sets( (a,b,c),(a,b),(a),() ) 와 같다.
group by rollup(department_id, gender) 은
group by grouping sets( (department_id, gender), (department_id), () ) 와 같다.
2. cube(a,b,c) 은 grouping sets( (a,b,c),(a,b),(b,c),(a,c),(a),(b),(c),() ) 와 같다.
group by cube(department_id, gender) 은
group by grouping sets( (department_id, gender), (department_id), (gender), () ) 와 같다.
*/
''국비지원'의 시작' 카테고리의 다른 글
| 오라클 비긴즈 06 ( Set Operator [ UNION ] ) (0) | 2023.02.13 |
|---|---|
| 오라클 비긴즈 05 ( JOIN ) (0) | 2023.02.10 |
| 오라클 비긴즈 03 ( VIEW ) (0) | 2023.02.07 |
| 오라클 비긴즈 02 ( 기타함수 (CASE WHEN ... 함수 , DECODE 함수 ) ) (0) | 2023.02.06 |
| 오라클 비긴즈 01 ( SELECT의 처리순서, Null 처리함수) (0) | 2023.02.03 |